索引介绍
索引是排序的,用于快速查找的特殊数据结构,它定义在作为查找条件的字段上,又叫key(键),索引通过存储引擎来实现。InnoDB使用B+Tree索引。
优点:
- 索引可以降低服务需要扫描的数据量,减少了IO次数
- 索引可以帮助服务器避免排序和使用临时表
- 索引可以帮助将随机I/O转为顺序I/O
缺点:
- 占用额外空间,影响插入速度
管理索引
创建索引:
CREATE [UNIQUE] INDEX index_name ON tbl_name (index_col_name[(length)],...);ALTER TABLE tbl_name ADD INDEX index_name(index_col_name[(length)]);范例:两种给students表格的name字段创建索引的方法
CREATE INDEX idx_name ON students(name);
ALTER TABLE students ADD INDEX idx_name(name);删除索引:
DROP INDEX index_name ON tbl_name;ALTER TABLE tbl_name DROP INDEX index_name(index_col_name);查看索引:
SHOW INDEX FROM [db_name.]tbl_name;优化表空间:
OPTIMIZE TABLE tb_name;EXPLAIN 工具
EXPLAIN命令可以分析索引的有效性,获取查询执行计划信息,用来查看查询优化器如何执行查询。
语法:
EXPLAIN SELECT clause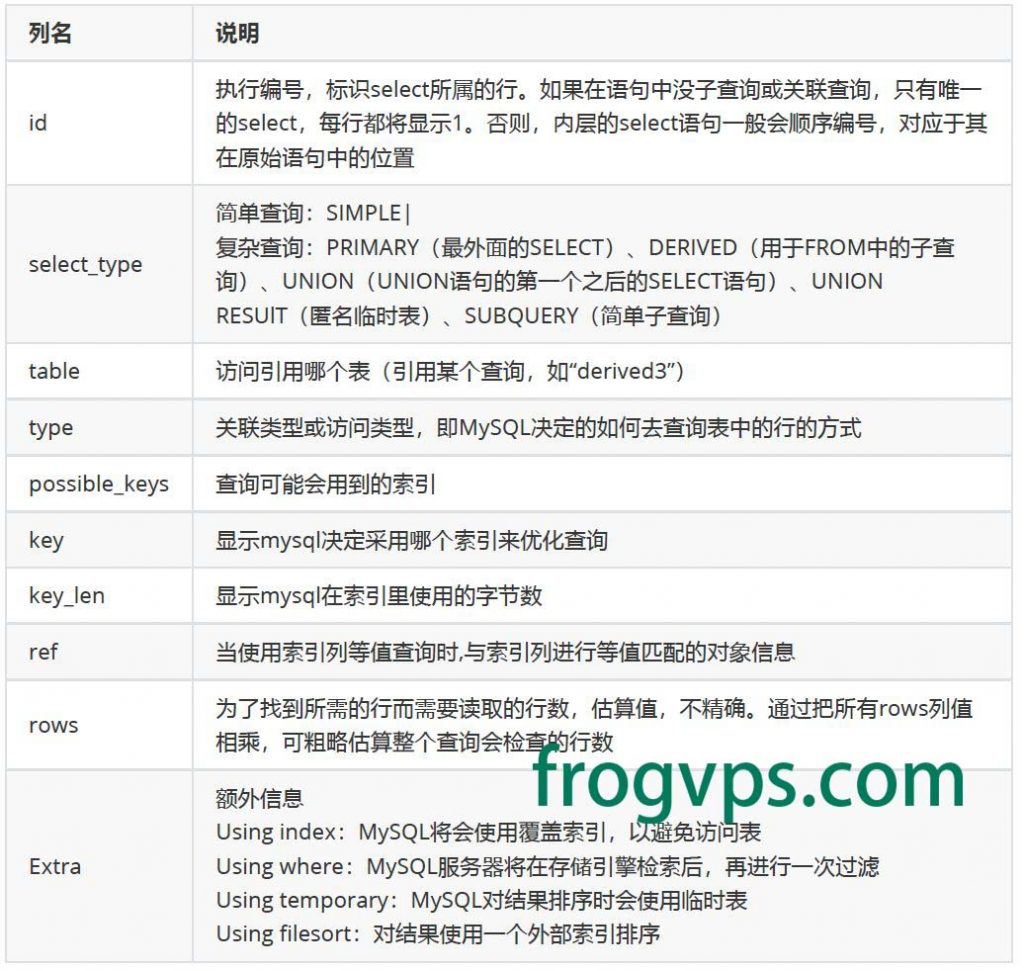
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
NULL> system >const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。

PROFILE 工具
设置系统变量profiling后,可以查看语句执行的时长和详细过程。(此功能在未来的版本会被弃用)
SET profiling = ON;查看语句执行过程
SHOW profiles;显示某条语句更详细的执行步骤,#表示语句编号
Show profile for query #;显示某条语句cpu的使用情况
Show profile cpu for query #;